AI appointment scheduling is no longer a novelty—an AI voice assistant for appointment scheduling can take calls and chats, propose available slots, and confirm bookings 24/7 so your team only handles exceptions. This practical guide walks through the end-to-end technical flow, integration patterns with common booking systems and CRMs, a realistic pilot timeline, measurable KPIs, and a dedicated section on How an AI Front Desk Handles Calls, Chats, and Bookings 24/7.
How AI Voice Scheduling Works End to End
Direct technical path: audio input from the caller becomes structured booking data through a predictable pipeline: speech-to-text, intent and entity extraction, dialog manager and slot filling, business rules and availability checks, temporary hold/reserve with the booking system, confirmation and follow-up via SMS or email, and finally CRM/CDP updates for attribution.
Core stages and where integration matters
Speech-to-text and NLU: use a robust STT (for example, Google Speech-to-Text or Twilio voice with ASR) chained to an NLU engine such as Dialogflow CX or Rasa. Practical rule: tune intent models around the smallest viable vocabulary for bookings (service, date, time, client identity) before expanding to edge intents like cancellations or refunds.
Dialog manager and slot filling: the dialog system must implement deterministic slot rules. Ask for the minimum required fields, then confirm a single compact summary to avoid repeated turns. Over-engineered open dialogs increase transfers to humans — shorter, guided prompts work better in live call volume.
Availability check: call the booking API (Mindbody, Vagaro, Calendly, or Google Calendar) and return 2 slots, not 10.
Temporary hold: create a short-lived reservation (30–120 seconds) while you confirm details; reconcile unconfirmed holds with a background job.
Final commit & notifications: on confirm, push the booking to the system and send an SMS or email confirmation and a reminder sequence from your CDP.
Trade-off to watch: longer hold windows reduce race conditions but increase the share of blocked but unconfirmed slots; short windows improve availability but force an extra round-trip to the user. Choose based on peak load and average time-to-confirm for your customer base.
Concrete example: A boutique fitness studio routes phone calls to an AI voice assistant integrated with Mindbody. The assistant identifies the caller via phone number in Gleantap, checks class capacity, places a 60-second hold on an open spot, prompts the caller for confirmation, and on approval pushes the booking to Mindbody and sends an SMS confirmation and an automated 24-hour reminder.
Limitation & judgment: NLU accuracy is necessary but not sufficient. Real reliability comes from tight integration with booking APIs, conservative dialog flows, and robust conflict resolution (optimistic locking + background reconciliation). Many projects fail because vendors focus on intent accuracy but omit durable reservation logic.
Omnichannel continuity: preserve the same session context across voice, chat, and SMS so the assistant can resume a booking started on voice in web chat. See the section How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 for operational handoff patterns and escalation rules; session IDs and the Gleantap profile lookup are the practical glue.
Key operational tip: implement temporary holds + a reconciliation worker that expires stale holds after a deterministic window. This single pattern prevents nearly all double-bookings without heavy locking on the source booking system.
Next consideration: design error-handling paths explicitly – when the system cannot parse or the booking API is down, fall back to short voicemail capture, immediate human callback request, or a secure web confirmation link. These make the automation robust in production.
How an AI Front Desk Handles Calls, Chats, and Bookings 24/7
Core assertion: an effective AI front desk is a session broker and rules engine, not a standalone voice bot. It needs to maintain conversation context across phone, web chat, and SMS, enforce business constraints, and escalate cleanly when confidence or policy requires human review.
Operational flow and handoff rules
Start each interaction by resolving identity where possible (phone number, SMS token, or web session). Use that identifier to pull a customer profile from your CDP so the assistant can apply membership status, outstanding balances, or staff preferences without asking unnecessary questions. Then apply a deterministic sequence: capture intent and required slots, run availability and business-rule checks, place a short hold, confirm the booking, and push a final commit to the booking system.
Pass structured context to humans: include the filled slots, holdid, bookingapitraceid, call transcript link, and an NLU confidence score so an agent can pick up immediately.
Escalation thresholds: set confidence bands that map to behaviors (auto-book, confirm with user, or route to live staff). Avoid auto-booking on low confidence for regulated or high-value appointments.
Queue and callback handling: when outside staffed hours, capture intent and preferred callback windows, record a callback SLA, and surface the request in a prioritized queue rather than leaving it to voicemail.
Trade-off to plan for: richer context reduces friction but increases compliance risk. Practical compromise: store only a pointer to the secure customer record and pass minimal PII in the handoff payload. Let agents request the full record through an audited portal rather than embedding everything in the call transfer.
Business-rule complexity: many failures happen because resource constraints are under-modeled. Multi-resource bookings (room + staff + equipment) and minimum prep windows must be checked before a hold converts to a commit. Implement a lightweight rules engine that can express these constraints and fall back to human review when rules conflict.
Concrete example: A dental practice routes after-hours calls to an AI front desk. The assistant identifies the caller, collects minimal intake (reason for visit, preferred days), places a temporary hold on an available hygienist slot, sends a secure verification link for insurance details, and schedules the appointment. If the caller needs a specific dentist or the insurance verification fails, the system creates a prioritized callback ticket with the full context for the next business day.
Design the handoff so a human agent can act without asking the customer to repeat key facts; that saves time and preserves trust.
Operational tip: log holdid, committime, and reconciliation_status for every booking. Reconciliation jobs that clear stale holds within a deterministic window are the single most effective guard against phantom availability.
Next consideration: set your escalation and data-passing policies now—they determine whether 24/7 automation reduces workload or simply shifts friction to the morning shift. Plan those thresholds, test real calls, and iterate with agents involved from day one.
Integration Patterns with Booking Systems and CRM
Practical point: integration is the part that decides whether your AI appointment scheduling actually reduces work or just shifts complexity. The right pattern ties an AI voice assistant for appointment scheduling to booking engines and your CRM in a way that preserves availability accuracy, maintains customer identity, and keeps auditable state for handoffs.
Five integration patterns (pick one, or combine)
Direct API sync: the assistant calls the booking platform API (Mindbody, Vagaro, Calendly) to read and write reservations in real time. Best when the booking API is robust and supports idempotent create/update calls.
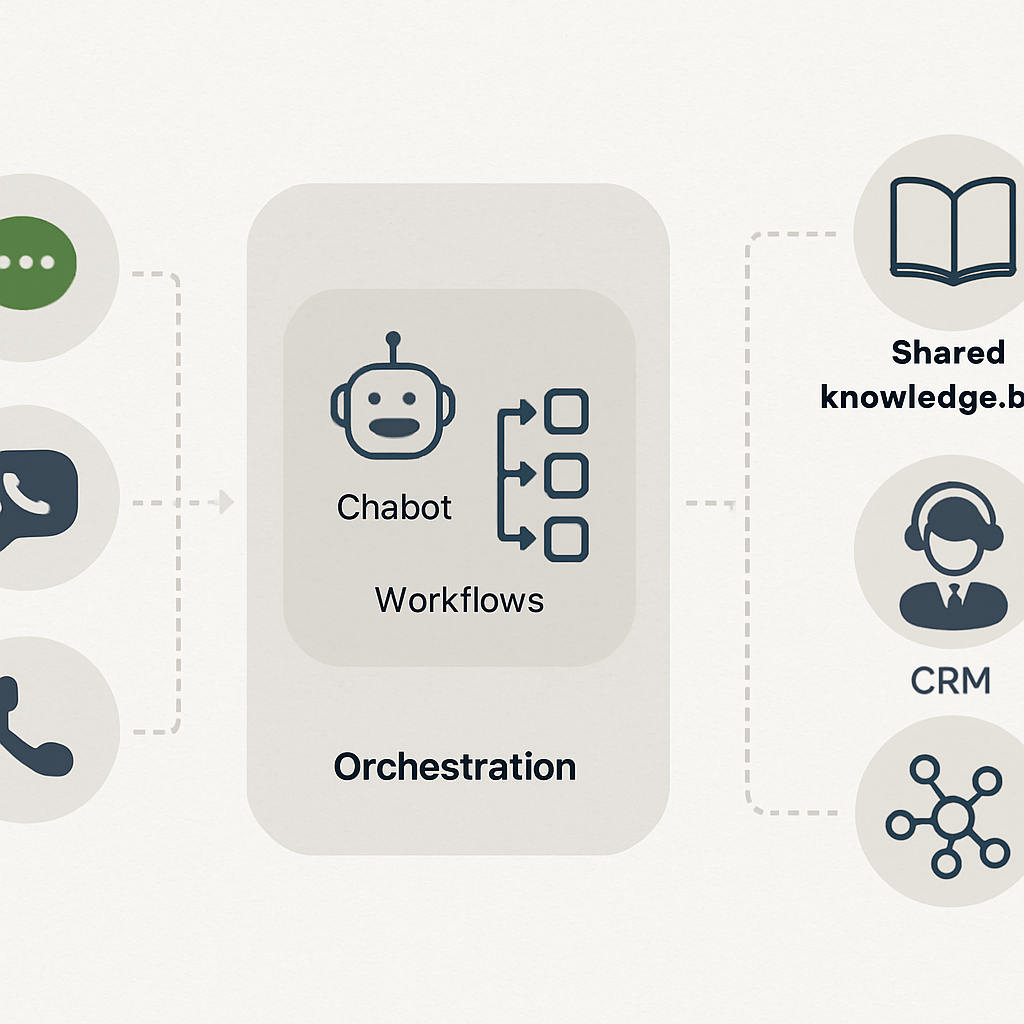
Orchestration layer (middleware): place a small service between the bot and systems that enforces business rules, translates field names, and handles retries. This is the most practical choice for legacy systems that have partial or flaky APIs.
Event-driven webhooks: subscribe to booking and CRM events so changes originating from POS, web, or staff apps update the assistant state quickly. Use this for high-concurrency operations and audit trails.
CDP-first approach: surface identity and preference data from your CDP (for example, Gleantap) to the assistant, but keep booking commits with the native scheduler. This keeps customer context centralized while preserving source-of-truth for bookings.
Calendar-proxy mode: if the platform lacks proper reservation semantics, maintain a short-lived proxy calendar that mediates requests and reconciles with the source system asynchronously.
Trade-off to plan for: middleware and proxy patterns add operational overhead but make complex rule sets manageable. Direct API sync is lower latency but brittle if the vendor changes endpoints or rate limits. For most B2C pilots, an orchestration layer wins on predictability.
Data flow and what to keep out of third-party systems
Data hygiene rule: send only the fields a booking engine needs. Do not mirror your entire CRM record into a booking platform. Instead, pass a minimally sufficient payload and store a reference key (crm_customer_id) so the assistant and agents can join records securely in your CDP.
Practical limitation: many booking APIs lack strong transactional semantics; you will see race conditions under peak load. Design the assistant to accept brief provisional reservations and expose a visible state (pending, confirmed, expired) in the CRM so staff and automated reconciliation jobs can resolve conflicts without calling customers.
Concrete example: A salon integrates a voice bot with Vagaro via an orchestration service. When a caller requests a 90-minute service, the bot queries Vagaro for matching slots, creates a provisional reservation token in the middleware for two minutes, collects a deposit link through a PCI-compliant gateway, and only then writes the confirmed appointment to Vagaro and updates the CRM. If payment times out, the middleware cancels the token and pushes an unconfirmed tag to the CRM for follow-up.
Operational judgement: avoid trying to make the assistant master every downstream system. Let the booking platform remain the single source of truth for schedule state, use your CDP for identity and campaigns, and put logic that spans systems into a thin, auditable orchestration layer. That reduces ambiguity during handoffs to humans and supports measurable reporting.
Integrations also shape how you implement How an AI Front Desk Handles Calls, Chats, and Bookings 24/7. If you centralize session and state in the orchestration layer, the same session can resume across phone, chat, and SMS while the CRM reflects the current workflow status for agents.
Key takeaway: favor an orchestration layer that enforces idempotency, surfaces reservation states to the CRM, and exposes a short reconciliation window. This pattern is the fastest path from pilot to reliable AI-driven calendar automation.
Next consideration: instrument end-to-end traces now (bot utterance -> reservation_id -> final commit). Without traceability you cannot reliably measure AI scheduling accuracy or run a clean rollback when things go wrong.
Industry Use Cases and Sample Conversational Scripts
Clear point: Real deployments succeed when you design scripts around the smallest set of required decisions for each industry flow. AI appointment scheduling systems win by eliminating needless prompts and handing off only when policy, payment, or complexity requires a human.
Practical trade-off: Short, guided prompts speed booking completion but raise the chance of missing nuance (staff preference, bundled services, or equipment needs). The right compromise is a minimal primary path plus a single optional branch for complex cases that escalates to an agent or a secure web form.
How to read the scripts below
Note: Voice prompts assume one-shot confirmations; chat variants assume the user can scroll or tap. For regulatory or payment-sensitive flows, collect only identifiers on the call and redirect to a secure channel for details. See the section How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 for channel continuity and handoff rules.
Use case Voice script excerpt Chat script excerpt
Family entertainment – birthday party reservation Assistant: Hello, this is the party desk. I have availability this Saturday at 11 AM for a 2 hour party. Do you want to reserve it for 20 guests? Customer: Yes. Assistant: Great — I will hold that slot and send a link to complete payment and guest details. Reply yes to confirm. Bot: Saturday 11 AM available for a 2 hour party for 20 guests. Tap Confirm to reserve and receive the payment link. [Confirm] [Ask a question]
Salon – color service with stylist preference Assistant: Which service would you like — full color, highlights, or a blowout? Customer: Full color with Sam. Assistant: Sam is available Wednesday 2 PM or Thursday 11 AM. Which works? Customer: Wednesday 2 PM. Assistant: Confirmed. You’ll get a reminder and a prep guide by SMS. Bot: Which service? • Full color • Highlights • Blowout. (User taps Full color) Any stylist preference? • Sam • Any. (User taps Sam) Sam is free Wed 2 PM — Confirm?
Telehealth clinic – intake + consent Assistant: I can schedule the appointment and send a secure intake link. Do you want a same-week slot or an appointment next week? Customer: Same-week. Assistant: There is a 3 PM slot tomorrow. I will secure it and text a secure intake link; are you comfortable receiving that link now? Customer: Yes — thanks. Bot: I can book a same-week telehealth visit and send a secure intake form. Select: • Tomorrow 3 PM • Next week. (User selects Tomorrow 3 PM) Confirm to receive secure intake link via SMS.
Retail – curbside pickup appointment Assistant: Pickup windows are 15 minute slots. I have 12:15 PM open. Do you want me to reserve 12:15 PM and hold it for five minutes while you complete payment? Customer: Yes. Assistant: Reserved — you’ll receive a pick-up code in SMS. Bot: Choose a pickup window: 12:00, 12:15, 12:30. (User taps 12:15) We’ll hold the slot briefly while you finish payment. Tap to continue to secure checkout.
Concrete example: A family entertainment center uses an AI voice assistant for appointment scheduling that proposes two party windows, takes a short verbal approval, and sends a secure payment link over SMS. When the guest requires a custom menu or extra rooms, the assistant creates a high-priority callback ticket with the reservation token so staff can finalize details without asking basic questions again.
Judgment: Many teams over-index on conversational flexibility instead of operational reliability. In practice, a rigid, predictable script that maps cleanly to your booking API and your staff’s exception process reduces errors and human follow-up. Start rigid, then expand utterance coverage as you log real failures.
Operational tip: log a short reservation_token and NLU confidence with every booking action. That single piece of metadata is what makes cross-channel continuation, reconciliation, and fast human pickup practical.
Next consideration: pick two high-volume flows to script verbatim, run them against real callers in a soft launch, and instrument where the assistant asks for clarifying turns. Use those spots to decide whether to add a branch, require a secure link, or escalate to a human.
Resources: For NLU patterns and slot strategies see Dialogflow documentation. To connect these scripts to a central customer layer, consider a CDP like Gleantap for identity and message orchestration.
Implementation Checklist and Pilot Timeline
Direct assertion: Treat the pilot as an engineering and ops gate, not a marketing demo. Success depends less on the voice model and more on airtight integration contracts, clear escalation gates, and a short, measurable feedback loop.
Prelaunch gates (what must be true before calls go live)
Identity and mapping: Verify caller ID or session token maps reliably to a customer record in your CDP (for example, use Gleantap to centralize identity) so the assistant can apply membership or blackout rules without extra questions.
Reservation semantics agreed: Have a documented hold/commit protocol with the booking system (who issues hold_id, how long holds live, and how to cancel stale holds). This prevents the most common double-booking failures.
Handoff payload defined: Define the exact structured payload passed to agents on escalation (filled slots, hold_id, NLU confidence, transcript URL). Agents must be able to act on that payload without re-asking core questions.
Minimum viable flows selected: Pick two high-volume workflows to automate fully and freeze the scripts for the pilot. All other cases route to a human queue with a clear SLA.
Pilot phases and milestone checklist
Phase 1 – Discovery & mapping: Confirm systems to integrate (booking platform, CRM/CDP, payment gateway), record peak hours and failure modes, and capture existing manual front-desk scripts.
Phase 2 – Integration and deterministic flows: Implement the orchestration layer that mediates between the AI assistant and the schedule source. Build provisional reservation logic and the reconciliation worker. Integrate notifications (SMS/email) and logging/traces to capture reservation_token -> commit paths.
Phase 3 – Internal test & agent dry-run: Run scripted calls and handoffs. Verify that escalations contain the minimal, actionable payload and that agents can complete tasks from the handoff without asking the customer to repeat facts.
Phase 4 – Soft launch: Open the pilot to a limited segment (by location, channel, or time window). Instrument key signals and keep humans on a low-latency standby for rapid rollback.
Phase 5 – Measurement and iterate: Use real interactions to expand NLU coverage, tighten hold windows, and tune escalation thresholds. Convert flows to production once error rates and reconciliation volume hit your acceptance criteria.
Acceptance criteria and operational stoplights
Green (go): AI handles a stable share of the pilot flows end-to-end with low reconciliation rate and agents report no repeat-capture complaints. Yellow (tune): High NLU success but elevated stale holds or API timeouts. Red (halt): Customer-facing errors causing misbookings or material data/consent issues.
Trade-off to plan for: Prioritizing broad conversational coverage early increases false positives and escalations. The practical path is conservative automation of core flows and progressive expansion based on live failure patterns.
Concrete example: An optometry clinic pilots after-hours phone booking for contact-lens fittings across two locations. The team integrates the assistant with their scheduling API, sets a short provisional hold token, routes any insurance-verification intent to next-business-day callbacks, and measures the share of successful end-to-end bookings versus callbacks to decide whether to widen the rollout.
Practical limitation: Expect the first iteration to trade conversational richness for operational reliability. Fixing reconciliation and handoff friction yields far more immediate value than adding more utterance variations.
Operational gate: require a visible reconciliation metric before scaling. If your reconciliation worker is reversing more than a small fraction of provisional holds, stop scaling and fix the hold/commit protocol.
How an AI Front Desk Handles Calls, Chats, and Bookings 24/7: Use the pilot to validate your session continuity model. Confirm that a booking started on voice can be resumed in SMS or web chat, and that the agent handoff exposes the same reservation_token and context so morning staff can finish work without customer repetition.
Next consideration: Decide your rollback and customer-notification plan before traffic hits the bot. A clear rollback procedure and a fast human triage path are what prevents pilot noise from turning into customer complaints.
Measuring Success and KPIs with Benchmarks
Measure what blocks work, not just what sounds good. For AI appointment scheduling, the right KPIs expose three operational facts: whether the assistant is closing real bookings, whether it reduces manual effort, and whether bookings are accurate and usable by staff after handoff. Instrument those end-to-end traces first; everything else is noise.
Core metrics to instrument
Primary success metrics: Track the percent of scheduling flows completed end-to-end by the AI voice assistant for appointment scheduling, the booking conversion rate from inbound contact to confirmed appointment, and the incidence of reconciliation events where a provisional reservation did not convert. These three tell you if the system is both productive and reliable.
AI-handled share: percent of requests fully handled by the virtual assistant scheduling flow (including confirmation and notifications).
End-to-end commit rate: of provisional holds created, how many become confirmed bookings within your hold window.
Average staff time saved: measured as minutes per booking removed from live-agent workload (use time-and-motion or system logs).
Call/chat abandonment: channel-specific abandonment after entering the booking path (indicates friction in the conversation flow).
Post-booking quality: percent of bookings requiring manual correction or duplicate fixes within 72 hours.
Practical trade-off: optimizing for a high AI-handled share often increases provisional holds and hence reconciliation work. If you push the assistant to auto-confirm uncertain intents, you reduce immediate handoffs but raise manual cleanup. Set conservative confidence thresholds for auto-commit on high-value or regulated appointments and permit lower thresholds for low-cost, high-volume bookings.
Benchmarks and a worked ROI example
Concrete example: A neighborhood wellness studio runs 1,200 appointment requests per month. They pilot an AI calendar assistant that handles evening calls. After instrumenting traces they observe: 18 percent of requests captured off-hours, a 70 percent conversion of provisional holds to confirmed bookings, and an average saved front-desk time of 6 minutes per confirmed AI-handled booking. They use these measured values to compute impact rather than relying on vendor claims.
Worked ROI (simple): if the studio’s average revenue per appointment is $45 and the AI captures 216 additional off-hour requests (18 percent * 1,200) with a 70 percent commit rate, that yields 151 incremental bookings = $6,800 gross. Subtract incremental monthly automation cost and staffing delta to calculate payback. Always show assumptions like hold window, confirmation rate, and average revenue in your board-level slides.
Attribution and experiment design: do not attribute every conversion to the bot without an experiment. Run a time-based A/B where half of comparable after-hours calls route to human agents and half to the assistant. Match on day-of-week and promotion exposure. Use reservation_token traces to join bot-originated commits with CRM revenue and exclude double-counted flows.
How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 matters to measurement. Session continuity lets you credit a booking that started on voice but completed in SMS; absent that continuity you will undercount AI impact and overcount manual work. Instrument session IDs, handoff payloads, and the timestamped lifecycle of hold -> commit -> reminder -> arrival so reporting reflects operational reality.
Key metric to watch: the reconciliation rate (provisional holds that expire or require manual resolution). If this exceeds a small, agreed threshold during pilot, stop expanding and fix hold semantics or latency—reconciliation is the fastest indicator of hidden operational cost.
Final judgment: prioritize direct, auditable signals over vague engagement metrics. A tidy dashboard showing AI-handled share, commit rate, staff time saved, and reconciliation exposes whether automation is reducing work or merely shifting it. Feed that data into weekly pilots, not just quarterly reports, and iterate fast.
Handling Edge Cases, Compliance, and Security
Start with the hard constraints. Regulatory obligations and predictable failure modes determine whether an AI appointment scheduling rollout reduces risk or multiplies it. Design choices that ignore edge cases or legal requirements are the fastest route to a paused pilot and angry staff.
Compliance essentials: For healthcare appointments you need a signed BAA, encrypted transport and storage, and clear limits on what the assistant records and retains. For card payments use a PCI-compliant processor and avoid capturing card data in transcripts or logs. Use vendor features that support end-to-end encryption (SIP/TLS for voice, HTTPS/TLS for APIs) and keep the minimal pointer to identity in downstream systems rather than mirroring full PII.
Privacy vs model improvement – the trade-off. Recording calls and saving transcripts helps debugging and improves NLU, but it raises legal and operational costs. Practical rule: only collect recordings with explicit consent, purge or redact sensitive fields before using data for training, and prefer synthetic or de-identified samples for model tuning.
Operational edge cases to hard-code now. Plan for partial or ambiguous utterances, booking API timeouts, payment failures, and simultaneous seat requests. Implement a short-lived provisional reservation token with an expiry and an automated reconciliation sweep that either commits, releases, or converts the request into a high-priority human ticket. Treat payment failures as a distinct state that triggers a secure payment link and a time-boxed follow-up rather than an immediate cancel.
How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 matters here. Maintain session continuity across channels using session IDs and reservation_token pointers, but gate sensitive actions when a channel is insecure. If a booking requires PHI or payment data, escalate the flow to a secure web form or an agent-assisted path that enforces re-authentication or one-time tokens.
Concrete example: A community clinic routes voicemail and after-hours calls to the assistant. The bot collects only date/time preferences and issues a provisional_token while sending a secure intake link via SMS. The clinic has a BAA with its cloud speech provider, stores only the token and an audit pointer in the CDP (Gleantap), and retains recordings for 30 days with automated redaction of any explicit health details before QA use.
Meaningful judgment: Teams commonly underestimate the cost of unresolved provisional bookings. A high volume of expired tokens is not a badge of progress; it is hidden operational debt. Fix reconciliation and payment-handling flows before expanding conversational coverage.
Quick, actionable controls to implement now
Minimum data in transit: pass only what the booking API needs and a crmcustomerid pointer; keep PII inside the CDP.
Provisional token policy: set an expiry, record token_owner, and run a reconciliation job every N minutes to resolve or escalate.
Consent & recording: inform callers at start, store consent flags, and separate QA data stores from production logs.
Must-have control: if your workflow touches PHI, require a BAA with every vendor that handles audio, transcripts, or storage. Without it you cannot legally use automated voice scheduling for protected health data.
Next consideration: instrument traceability for every booking lifecycle (session -> provisional_token -> commit/expire -> reminder -> arrival). Those traces are the only way to quantify hidden costs from edge cases and to decide whether to widen your How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 rollout.
Gleantap Integration Example and Implementation Notes
Direct integration pattern: Use Gleantap as the authoritative customer layer, a dedicated orchestration service for booking logic, and a conversational NLU like Dialogflow CX to parse voice and chat. Gleantap stores identity and messaging channels; Dialogflow handles intent/slot extraction; the orchestration layer enforces business rules, issues provisional reservations to the booking API (Mindbody, Zen Planner, or similar), and records lifecycle traces for audit and metrics.
Key implementation steps (high level)
Step 1 — identify and enrich: On incoming calls the orchestration service queries Gleantap by phone or session token to fetch membership status and blackout rules so the assistant asks fewer questions. Step 2 — capture intent: Dialogflow CX returns structured slots (service, duration, preferred time). Step 3 — provisional reservation: the orchestrator requests a short-lived hold via the booking API and returns a reservation_token. Step 4 — commit or release: after confirmation (and payment if required) the orchestrator converts the hold into a confirmed booking and instructs Gleantap to send confirmations and reminders.
Practical trade-off: Longer hold durations lower simultaneous-race failures but increase the chance of blocked availability that never commits. If your business is high-volume and short-duration (classes, curbside pickups) prefer short holds + rapid confirmation links; for high-value, low-frequency services (private training, clinical visits) allow longer holds and require a human or payment confirmation to commit.
Real-world instance: A massage studio routes after-hours phone traffic to Dialogflow CX linked to Gleantap. The bot recognizes the caller, extracts service and preferred day, asks a single confirmation prompt, then calls the studio’s scheduling API to create a 90-second hold. When the caller confirms, the orchestration layer commits the slot, triggers Gleantap to send an SMS confirmation and a 24-hour reminder, and writes the reservation_token and audit trace back to the CDP for reporting.
Operational notes that matter: Implement idempotency keys and per-request trace IDs so retries and webhook redeliveries do not create duplicate appointments. Log minimal PII in handoff payloads; pass crmcustomerid instead of full profiles for agent transfers and use an audited portal to fetch full records. Expect the booking API to be the weakest link—build predictable timeouts and a fallback that converts the call into a prioritized callback ticket rather than a silent failure.
How an AI Front Desk Handles Calls, Chats, and Bookings 24/7: Preserve session continuity by tying Dialogflow sessions to the Gleantap profile and the reservation_token so a booking started on voice can be resumed in chat or SMS without repeating details. That continuity is the operational difference between automation that reduces work and automation that creates morning cleanup jobs.
Design the orchestration layer to be the single place for business rules, hold/commit semantics, and reconciliation. That centralization buys predictable behavior and measurable traces.
Implementation must-haves: enforce idempotency, implement a deterministic hold expiry and reconciliation worker, store only pointer IDs in third-party systems, and require a BAA for any flow touching PHI. Without these you will surface hidden operational costs quickly.
Frequently Asked Questions
Direct answer up front: most vendor and implementation questions have pragmatic trade-offs — pick the option that reduces morning cleanup and keeps reconciliation tractable, not the one that promises conversational perfection. AI appointment scheduling and an AI voice assistant for appointment scheduling are tools; their value shows up in integration discipline, escalation rules, and traceability.
Operational and vendor questions
Q: Will the assistant break my existing booking system or CRM? No—if you treat the booking platform as the source of truth and place a thin orchestration layer between the assistant and downstream systems. That orchestration layer should handle idempotency keys, temporary holds (reservation_token), and clear rollback rules so retries and webhook redeliveries do not create duplicates.
Q: How do I choose between cloud ASR/NLU and an on-prem alternative for protected data? Choose cloud services for speed and accuracy unless regulation forces otherwise. When PHI or local data rules apply, prefer vendors that sign a BAA and offer private-cloud or dedicated-instance options. The trade-off: on-prem adds compliance comfort but increases latency, cost, and maintenance burden.
Q: Who owns call transcripts and training data? Contractually define ownership up front. Keep production logs separate from training datasets, require redaction of PII before use, and include a clause that data used to improve shared models is de-identified. This prevents unexpected exposure and preserves auditability.
Q: What should be included in an SLA for availability and accuracy? Insist on trace-level SLAs: uptime for call ingestion, median API response times for availability checks, and maximum allowable reconciliation rate. Avoid vague accuracy guarantees; demand reproducible metrics tied to your pilot flows.
Implementation and change-management questions
Q: How do you prevent AI automation from creating more morning work? Stagger rollout by funneling complex or low-confidence cases to humans and instrument a reconciliation dashboard that shows expired reservation_tokens. If expired holds or manual corrections rise above your threshold, pause expansion and fix the orchestration rules first.
Q: Can the assistant handle deposits or payments? Yes—integrate a PCI-compliant gateway and use off-call payment links when possible. Payment on the call is feasible but increases compliance scope and UX complexity; the usual pattern is a provisional hold + secure payment link + commit on webhook confirmation.
Three vendor checks before you buy: Confirm BAA/PCI capabilities if needed; verify real examples of hold -> commit reconciliation; require trace-level logging to join reservations to payments and reminders.
Concrete example: A neighborhood spa configured a voice assistant to capture after-hours bookings. Calls are routed to Dialogflow, the orchestrator creates a 90-second reservationtoken in the booking API, and the assistant texts a secure Stripe link. When payment webhook confirms, the orchestrator writes the confirmed appointment to the booking system and the spa sees the reservation appear in their daily schedule with the same reservationtoken for audit.
Practice note and judgment: Teams often chase broader conversational coverage before the reconciliation and handoff framework is stable. That leads to high escalation volume and lost trust. Invest early in deterministic flows, traceability, and the human handoff payload rather than natural-language breadth.
Key action: Run a two-week test that routes only one or two flows to the assistant, instrument reservation_token lifecycle, and require a sub-5 percent reconciliation rate before adding more complex cases or languages. This single gate prevents most operational debt.
See the section How an AI Front Desk Handles Calls, Chats, and Bookings 24/7 for concrete handoff payloads and session-continuity patterns that make measurement and agent pickup reliable across channels.
Next steps you can implement this week: (1) Define your acceptable reconciliation threshold and add it to the vendor contract; (2) require reservation_token tracing in proofs of concept; (3) set up a pilot dashboard that shows token state, commit events, and manual corrections in real time. Those actions convert vendor demos into operational checks.