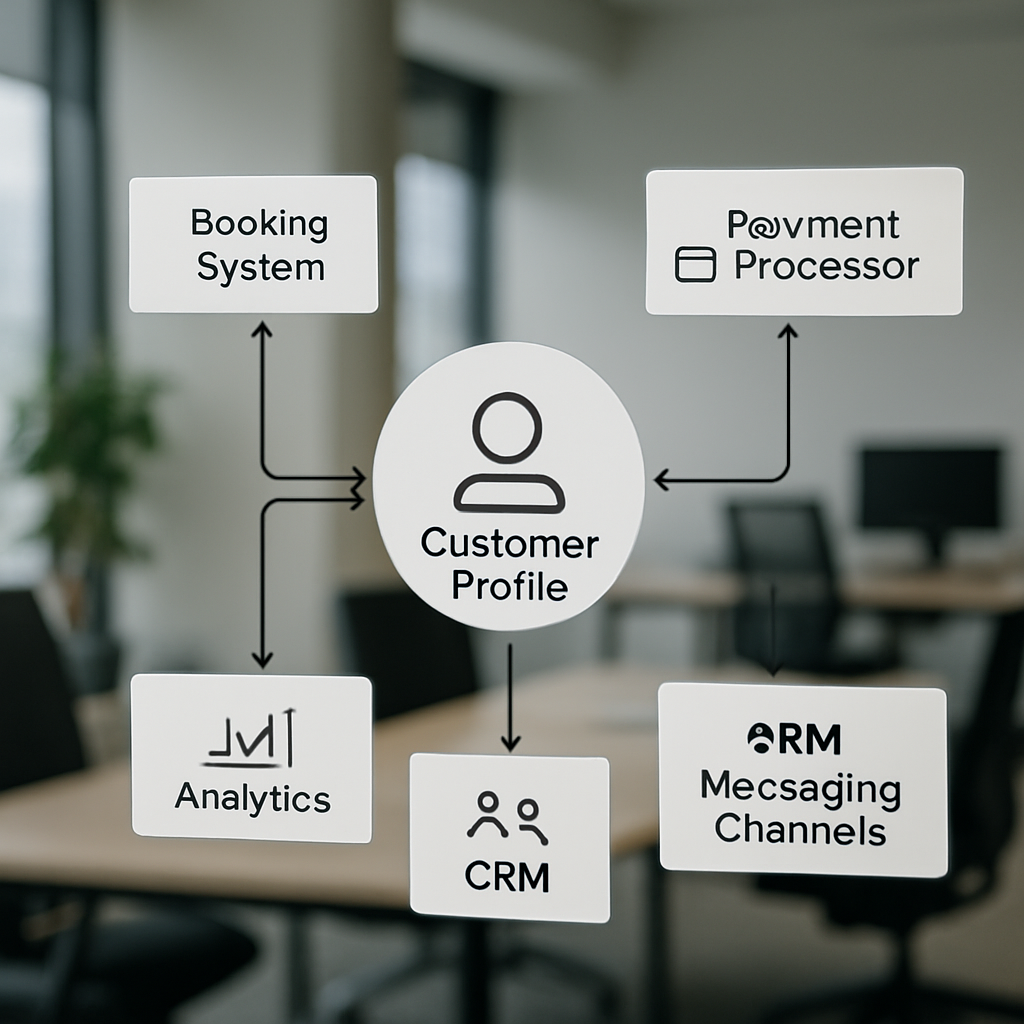
Low visit frequency and early churn are usually not marketing failures but data failures: fragmented booking, attendance, and payment systems make timely, personalized outreach impossible. The Evolution of Gym CRM: From Contact Management to Member Intelligence shows how low visit frequency and early churn stem from fragmented data systems, and how unified member profiles enable proactive, personalized engagement with the right message at the right time through clear segmentation, workflows, measurement, and a practical 90-day rollout plan. A fitness member engagement CRM brings those sources into unified profiles so you become proactive rather than reactive, targeting the right members with the right message at the right time. This guide gives a step by step playbook—exact segment rules, sample workflows and message cadences, measurement formulas, and a 90 day rollout you can start using this week.
1. Start with the data you need and how to unify it
Core assertion: a fitness member engagement CRM is only useful if the profiles inside it are complete, deduplicated, and trustable. Focus first on a short list of fields you actually need to run automations, not every column your systems can export.
Essential fields to standardize in the single member profile
Key fields: member_id (source system id), join_date, last_visit_date, visit_frequency_30d, lifetime_spend, package_balance, preferred_class_types, assigned_trainer, and consent flags with timestamp and source. Store both raw event history and a small set of derived fields that your workflows will read directly (for example visitfrequency_30d).
- Priority data sources: scheduling/attendance (e.g. Mindbody), POS/payments (Stripe, Square), membership records, NPS/surveys, and mobile app events.
- Minimum sync cadence: daily batch for core fields, with event streaming for time-sensitive triggers like first booking or class cancellation.
- Dedup rule to implement first: prefer authoritative id (membership id) then match on email + normalized phone + last payment hash; if two records conflict, preserve the most recent consent timestamp.
Practical trade-off: real-time event streaming is ideal for immediate onboarding and no-show triggers but raises engineering and cost overhead. If you lack engineering bandwidth, implement a 1–4 hour near real-time job for critical events and daily batches for aggregated metrics. This gives acceptable responsiveness without a full event pipeline.
Data quality checklist: run these weekly sweeps: detect duplicate emails/phones, flag missing consent, reconcile mismatched membership statuses between POS and scheduling, and backfill preferredclasstypes from attendance history when explicit preferences are empty.
Concrete example: A regional studio maps Mindbody attendee events to a CRM profile, writes a transform that calculates visit_frequency_30d from raw class_check_in events, and sets opt_in_sms using the consent timestamp from its sign-up form. They run a nightly dedupe that merges duplicate profiles by keeping the newest consent and package_balance — this allows them to trigger a welcome SMS within hours of the first confirmed booking rather than days later.
Common misunderstanding: teams often hoard every field because it seems useful later. In practice this creates noise: inaccurate or stale fields drive bad segmentation. Start with a tight canonical model, then add attributes only when a clear campaign needs them.
Implementation tip: capture consent with source and timestamp, enforce a single source of truth for membership status, and expose three operational views from your CRM: raw event log, canonical profile, and campaign-ready attributes. If you want a checklist to run this, see the Gleantap integration guide at Gleantap Features.
Next consideration: once profiles are trustworthy, decide which fields will be derived in-CRM versus precomputed in your data layer — that decision affects sync cadence, cost, and how quickly you can iterate on segments and automations.
2. Build actionable segments with clear rules and examples
Direct point: Segments should be executable rules that feed automations, not fuzzy labels you hope feel useful. If you cannot write a SQL-like filter for a cohort and a single CTA your ops team can run, it is not actionable.
Core actionable cohorts and exact rules
| Segment | Rule (example filter / SQL-like) | When to use / Priority |
| cohortnew30d | WHERE join_date >= current_date – INTERVAL 30 days | Send welcome + onboarding sequence; high priority for activation |
| cohortatrisk14d | WHERE last_visit_date <= current_date – INTERVAL 14 days AND visits30d >= 3 AND membership_status = active | Trigger gentle reactivation flow for likely churn candidates |
| cohorthivalue | WHERE lifetime_spend >= 1200 OR visits365 >= 48 | High-touch upsell and retention; human follow-up escalation |
| cohortclasslovers | WHERE (SELECT COUNT(*) FROM class_check_ins WHERE member_id = m.id AND date >= current_date – INTERVAL 30 days) >= 6 | Promote class passes, new class types, or loyalty rewards |
| cohortptprospect | WHERE assignedtrainer IS NULL AND (pt_inquiry_flag = TRUE OR visits_30d >= 3 AND avg_booking_value >= 20) | Targeted PT offers and consult booking |
Practical insight and trade-off: Finer segmentation increases relevance but creates operational overhead. Start with 6 to 8 core cohorts you can support with distinct CTAs and reporting. If you create dozens of tiny segments, you will either drown in message variants or need a sophisticated orchestration engine and strong QA to avoid sending contradictory messages.
- Naming convention: use prefixes to make intent obvious — cohort for behavior groups, action for lists tied to a campaign, holdout_ for tests.
- Minimum population rule: prefer segments with at least 50–100 members for regular cadence campaigns; smaller segments are fine for one-off VIP outreach.
- Include fallbacks: always provide defaults for dynamic fields (example: if favoriteclass is null, show topweekly_class) to avoid broken messages.
Concrete example: A boutique studio built cohort_at_risk_14d using the rule above and connected it to a three-step workflow: SMS reminder (day 0), email with a curated class list (day 3), and a staff task to call members with lifetime_spend > 600 after day 7. Because the segment used explicit numeric thresholds, the studio could run a randomized holdout and measure incremental visits over 30 days without ambiguous attribution.
Judgment you need to accept:Behavioral segments built from attendance and transaction signals are far more predictive than demographic-only lists. Rely on transaction and attendance thresholds for primary segmentation; reserve demographics for secondary personalization (tone, imagery, or channel preference).
Build segments that answer two questions: who is this member and what do we want them to do next. If a segment cannot produce a single measurable action, retire it.
Implementation tip: keep segment definitions versioned and documented (why the threshold exists, who owns it, expected audience size). For a fast how-to and examples you can copy, see the Gleantap segmentation guide at How to Segment Your Members.
3. Design onboarding sequences that increase first 30 day retention
Direct point: The onboarding sequence must convert a new sign up into a habit within the first month. Design a small set of timed, measurable touches that move members from curiosity to scheduled visits – aim for an activation metric such as three visits in 30 days and build every message to that single outcome.
Blueprint – timed touchpoints and message intent
- T0 – near immediate (first 2 hours): send a short SMS confirming booking or membership and giving one easy next step – example CTA book a companion class or reply for trainer intro. Use {{first_booking}} and {{location}} placeholders.
- Day 1: deliver an email with an actionable class guide tailored to the member’s first booking and recommended time slots. Include a single primary CTA that opens the booking flow.
- Day 3: trigger a personalized SMS from an assigned trainer or coach if available – tone should be human and specific, for example mention the class they booked and offer a quick tip or ask if they want help reserving more slots.
- Day 7: automated check-in via email or push for app users with dynamic social proof – show real attendees, upcoming classes that match their preferences, and a calendar button to reserve.
- Day 14: targeted incentive only if activation target not met – offer a consult, a guest pass, or a limited time class credit; avoid straight percentage discounts that train price sensitivity.
Practical tradeoff: SMS converts faster but increases compliance and opt out risk – keep SMS count low and always respect consent flags. Email supports richer personalization but has longer response lag. Use app push sparingly for engaged mobile users. Balance speed with legal and operational constraints – a heavy SMS first week will boost bookings but raise unsubscribe rates and front desk calls.
Operational rules to prevent message collisions: implement channel suppression logic that prevents sending an email and an SMS with the same CTA within 24 hours; create a front desk visibility feed so staff can see recent automations and avoid duplicative outreach; version every template and preview populated messages for top 10 members in the segment before launching.
Measurement and experimentation
- Primary KPI: 30 day activation rate = members with >= 3 visits in 30 days divided by new joins in period.
- Per-touch metrics: booking click-through rate, booking to visit conversion, opt out rate per channel, and time-to-second-booking.
- A/B tests to run: immediate SMS versus delayed SMS, trainer intro message versus generic tip, and consult offer versus class credit for the Day 14 incentive.
Concrete example: A four-location studio implemented this blueprint and replaced manual welcome calls with an automated trainer intro SMS followed by a Day 7 email. They reduced manual outreach hours by two staff days per week and reported a meaningful lift in second week bookings; they used a randomized holdout to verify the lift before scaling the incentive.
Judgment call: Over-personalization without fallbacks breaks at scale. Build a small set of reliable templates with robust default values for dynamic fields and limit message variants to what your QA process can validate. Prioritize operational reliability over crafting ever more granular copy.
Launch the sequence for a single location or cohort, run a holdout test for 30 days, then iterate – small reliable wins compound faster than perfect personalization.
Launch checklist: ensure join_date, last_visit_date, assigned_trainer, opt_in_sms and preferred_location exist in the profile; preview templates with real data; set suppression windows; create a staff task rule for high value members who remain inactive after day 14. For integration guidance see Gleantap Features and onboarding resources at Gleantap Resources.
4. Create reactivation and at risk workflows that run automatically
High leverage fact: Automated reactivation sequences cut avoidable churn faster than general broadcast marketing because they act on a specific behavioral deterioration signal and convert lapsed members before they forget why they joined. A properly configured fitness member engagement CRM lets you operationalize that signal and keep outreach proportional to value.
Practical consideration: shorter windows catch members who are drifting; longer windows target lapsed members who need a stronger reason to return. Choose which you automate based on staff capacity and margin on a reactivation offer.
Recommended staged workflow (conditional, automated)
- Stage 1 – Gentle nudge (automated): send one short SMS referencing recent activity (example: you attended 4 classes this month — here are 3 classes this week that fit your schedule). Include a single Book CTA and a 72 hour suppression before repeating.
- Stage 2 – Value reminder (automated, 4–7 days after): if no booking, send an email with social proof, two personalized class recommendations, and an offer framed as a limited add-on (for example a 2-class pack at a small premium). Track click-to-book conversion.
- Stage 3 – Escalation (human handoff after 10–14 days): if still no response and member lifetime_spendor visit_rate exceeds your VIP threshold, create a staff follow-up task with a script and phone number. Automate task creation and include the member profile link so staff have context.
Trade-off to accept: aggressive automated escalation increases returns but also increases front desk calls and false positives. If you lack staff, tighten triggers (higher minimum visits_90d) or increase wait windows so human follow-ups target only the highest probability wins.
Measurement and test design: run a randomized holdout (suggested 10% control) for each workflow. Primary metric: 30-day reactivation rate = members who booked and attended at least one class within 30 days of trigger ÷ total members in cohort. Secondary: incremental revenue per treated member over 60 days. Use this to validate offer economics before rolling out broader incentives.
Concrete example: A three-studio operator implemented a two-stage flow: SMS nudge (72 hour window) then email with a two-class credit offer. They set human follow-up only for members with >650 USD lifetime spend. Over a 60 day test the treated group returned at a 28% higher rate than the 10% holdout and the uplift paid for the credits within three months.
Key judgment: automated outreach needs conservative escalation rules. Most studios win by automating the first two touches and reserving human effort for high-value or long-tenured members.
Quick checklist before you go live: define trigger filter(s), set channel suppression windows, craft 2–3 fallback values for dynamic fields (favorite_class, last_booking_date), decide VIP threshold for human handoff, and run a 30–60 day holdout test. See implementation notes at Gleantap Features and rollout templates at Gleantap Resources.
Next consideration: pick one trigger and one incentive, launch a small randomized test, and then expand only after the economics and staff load prove out.
5. Use personalization at scale with dynamic content and AI driven predictions
Direct point: Use dynamic content blocks plus simple predictive signals to choose the offer, tone, and channel for each member — not to write every message by hand. This is how a fitness member engagement CRM scales personalization without exploding operational burden.
How to wire dynamic content into campaigns
Populate with reliable fields: drive templates from a short set of high quality attributes — for example {{last_visit_date}}, {{last_class}}, {{favorite_instructor}}, and {{remaining_credits}}. Avoid dozens of optional placeholders; each additional field raises the chance of broken or awkward copy when data is missing.
Fallbacks and previews matter: always set fallbacks (for example show Top Weekly Class when {{favorite_instructor}} is null), and preview messages for 10 real members across segments before you publish. In practice the majority of personalization errors come from missing joins or stale syncs, not bad copy.
- Channel selection by score: route messages to SMS when predicted open probability for email is low, otherwise send email for richer content.
- Offer sizing by risk: use a churn risk decile to pick an incentive band — low-risk get reminders, mid-risk a class credit, top-risk a time-limited consult or guest pass.
- Next best action: score possible CTAs (book class, schedule PT, redeem credit) and surface the highest expected revenue or retention lift as the primary CTA.
Practical limitation: predictive models are only as good as recent behavior. If your attendance or payment data lags by days, the churn score will systematically underperform for short-window triggers. The trade-off is between engineering cost for near real-time syncs and the value of catching members before they churn — pick the level of freshness you can maintain reliably and build rules around that cadence.
Concrete example: A three-studio operator used a churn score (trained on attendance + booking cadence + cancellations) to split at-risk members into two treatments: those in deciles 7-9 received an automated email with a single personalized class recommendation using {{last_class}}; decile 10 received an SMS plus a staff task for VIP follow-up. Over a 60 day pilot the model-directed routing reduced unnecessary staff calls by 40% while concentrating human effort where it moved the needle.
Judgment you must apply: do not let AI replace campaign design. Models should inform which variant to send, not generate uncontrolled, member-specific offers. In practice studios that let models pick from a small catalog of tested messages see predictable, auditable gains; those that auto-generate ad hoc copy create liability and inconsistent brand tone.
Operational checklist before you flip to model-driven personalization: confirm sync latency for attendance and payments, define churn-score thresholds and corresponding offers, build robust fallbacks for every dynamic field, preview templates using real profiles, and establish a 10% holdout for initial experiments. For integration notes see Gleantap Features.
Key takeaway: use AI to choose between a small number of validated message variants and channels — this delivers scalable relevance without the QA nightmare of fully bespoke copy.
6. Orchestrate omnichannel outreach and set frequency rules
Direct point: Orchestration is not about using every channel; it is about coordinating the one call-to-action so members receive a single, coherent prompt across channels. Treat CTAs as the unit of control and build rules that lock a CTA for a defined period before switching channels.
Channel intent and practical routing
- SMS for immediacy: time-sensitive confirmations, class cancellations, and last-minute seat openings — route only when the expected action window is under 72 hours.
- Email for depth: schedules, educational sequences, and receipts where members may want links, images, or attachments; reserve email for actions that require context.
- Push for habitual nudges: quick check-ins and streak reminders for app users who have demonstrated mobile engagement.
- Phone/human outreach for high-touch wins: use only after automated attempts fail and for members above a VIP threshold — automate the task creation but not the call script.
Frequency rules (practical defaults): limit promotional SMS to roughly 1–3 per month depending on member engagement; allow transactional SMS (bookings, cancellations) outside that cap but track them separately. For email, use an engaged cadence of 2–3 messages per week and a quieter hygiene stream of 1–2 per month for low-engagement members. These are starting points — tune them to your unsubscribe, reply, and front desk load.
Suppression and CTA-locking: enforce a CTA lock (for example 48 hours) so the same CTA does not fire across two channels immediately. Prefer CTA-level suppression over blunt channel caps — avoiding duplicate CTAs reduces member confusion more than simply limiting channel counts.
| Message Priority | Primary Channel | Secondary Channel | Max touches (30 days) |
| Transactional (booking, receipt) | SMS | Unlimited (count separately) | |
| Retention nudge (at-risk) | SMS | 2–4 | |
| Awareness/campaign (new programs) | Push | 1–3 | |
| VIP outreach | Phone (task) | Personal SMS | Human-determined |
Operational alignment that’s often missed: publish a short, read-only feed for front desk and trainers that shows the last 7 days of automations sent to any member they interact with. In practice this single visibility change cuts duplicated outreach and reduces member complaints more than perfecting copy.
Concrete example: A three-location studio ran a 14-day fitness challenge where the CTA was enroll-and-book. They locked that CTA for 72 hours after an SMS invite; if unopened, the system sent a follow-up email with resources. Members who clicked the email were routed to push reminders. The studio piloted this as a control-test and used the CTA-lock to measure channel lift cleanly before scaling.
Quick checklist before you activate: define CTA ownership, implement CTA-lock windows, separate transactional counts from promotional caps, set quiet hours per locale, surface recent automations to staff, and verify consent records for SMS following FTC guidance. For platform integration notes see Gleantap Features.
Trade-off to accept: adding channels increases reach but also increases complexity and support volume. Automate early touches and reserve human outreach for high-value members; your staffing model must follow your orchestration complexity.
Key takeaway: If a campaign cannot demonstrate incremental visits or revenue within 60–90 days after accounting for incentives and staff costs, treat it as an experiment and iterate. For dashboard templates and cohort examples see Gleantap Resources and industry benchmarks at IHRSA.
Final consideration: measurement should reduce uncertainty, not create a reporting circus. Automate the key charts, schedule concise weekly reviews, and require a clear go/no-go metric before committing budget or headcount to any engagement program.
8. Ensure privacy, consent, and regulatory compliance for messaging
Straightforward fact: compliance is not a legal footnote — it is a core operational control that determines whether your campaigns keep members and avoid fines. Treat messaging permissions, suppression, and auditability as features of your fitness member engagement CRM, not afterthoughts.
What to put in place before you send any campaign
Start by making three things non-negotiable: verifiable opt-in, universal suppression across channels, and easily exportable consent evidence. Practically that means every profile must carry a consent record that shows who agreed, how (web form, paper waiver, in-app toggle), and when — plus the version of the terms they accepted and the channel(s) permitted for marketing.
Legal anchors you need to respect: in the United States follow TCPA and the FTC guidance on text and robocall rules (FTC guidance); in the EU apply GDPR principles like purpose limitation and data minimization; in Canada observe CASL. If you operate across jurisdictions, default to the most stringent local rule for any member to avoid cross-border mistakes.
- Implementation step 1: capture consent with context — log the UI element, the exact copy, and a timestamp so you can reproduce what the member saw.
- Step 2: enforce a single suppression layer — a universal opt-out must block SMS, email, and push for promotions instantly and be respected by campaign rules before any send.
- Step 3: separate transactional messaging — design your system so operational messages (booking confirmations, safety notices) can be sent independently of marketing consent, and document why each message is transactional.
- Step 4: maintain a consent audit export — build an easy export that legal or auditors can run showing consent history for any member.
- Step 5: lock down access and retention — encrypt PII at rest, restrict who can change consent flags, and implement a data retention schedule that matches privacy obligations.
Practical trade-off: double opt-in reduces deliverability friction and complaint rates but lowers the size of your SMSable audience. Many small studios see a short-term drop in available contacts after tightening consent, but fewer legal headaches and better long-term engagement because messages go only to people who want them.
Common mistake to avoid: using pre-checked boxes, burying opt-in language in long waivers, or mixing marketing consent with general liability release. These are fragile defenses — regulators and carriers will treat ambiguous consent as no consent at all. When in doubt, treat unclear records as opt-out and re-permission the member with a clear, explicit prompt.
Concrete example: A four-location studio standardized its signup flow to present a concise marketing opt-in checkbox and recorded the source (site, iPad, or paper). They moved all campaign logic to read that consent flag in real time and disabled promotional SMS sends for anyone lacking explicit opt-in. The immediate effect: the studio sent fewer promotional texts but cut complaint tickets by two-thirds and avoided a carrier suspension after a busy promotional weekend.
If your CRM cannot show who opted in, where, and when for a single member — do not use it for SMS marketing until it can.
Quick compliance checklist: log consent source + timestamp; implement global suppression lists; distinguish transactional vs promotional messages; provide one-click opt-out in every SMS and a preference center for email; build exportable consent history; apply the strictest local law per member. For integration guidance see Gleantap Features and consult FTC guidance.
Next consideration: prioritize making consent records searchable and auditable before adding any new SMS campaigns. That order keeps you compliant and prevents a noisy inbox, regulatory risk, and the hidden cost of staff time spent resolving member complaints.
9. Implementation roadmap and staffing plan
Start with a tight 90-day delivery with named owners — that beats an open-ended project plan every time. Break the work into concrete phases you can staff, measure, and stop if it fails economics.
Phased rollout (practical cadence)
Phase 1 (Days 0–30): consolidate core data, validate consent flags, and publish 3 campaign-ready attributes (join_date, last_visit, visit_frequency_30d). Keep scope narrow so you can begin automations without waiting for a perfect data model.
Phase 2 (Days 31–60): enable the minimum viable automations — one onboarding flow and one at-risk reactivation sequence — and route outputs into a weekly campaign health report. Use a 10% randomized holdout from day one.
Phase 3 (Days 61–90): iterate on messaging, add one personalization rule (for example offer sizing by churn_decile), and implement human escalation tasks for VIPs. Decide whether to scale based on the ROI gate in the info box below.
Who does what (realistic weekly commitments)
| Role | Suggested weekly hours | Primary responsibilities |
| Data owner (could be vendor or contractor) | 4–8 | Manage integrations, monitor sync health, own dedupe rules and freshness SLAs |
| Campaign manager (marketing/membership lead) | 6–10 | Design flows, own templates, run A/Bs, review weekly campaign health |
| Front desk liaison (operations) | 2–4 | Surface member exceptions, confirm human handoffs, check suppression/consent issues |
| Analytics owner (part-time or outsourced) | 3–6 | Build KPI reports, run holdout analysis, compute incremental revenue and cost |
Practical trade-off: hiring a contractor for integrations speeds deployment but reduces internal knowledge transfer. If you expect ongoing experimentation, budget for at least one part-time staffer who can own templates and QA rather than relying on an external one-off implementation.
Operational constraint to watch: automation reduces manual touches but increases monitoring needs. Expect an initial spike in front desk questions and a steady weekly review commitment to keep suppression and templates error-free; plan those hours into staffing rather than assuming zero maintenance.
Real example: A two-location boutique studio staffed a 90-day push with a part-time data contractor (6 hrs/wk), a membership manager (8 hrs/wk), and front desk coverage (3 hrs/wk for QA). They launched the onboarding + at-risk flows in 45 days, used a 10% holdout, and reduced weekly manual outreach time by 7 staff-hours after the first month while maintaining a positive ROI on offered class credits.
Success gate (acceptance criteria): 1) 30-day activation up at least X percentage points versus holdout (define X before launch); 2) decrease in manual outreach hours by at least 30% per week; 3) no compliance incidents and opt-out rate under your target threshold. If two of three are unmet after 90 days, pause and reassess offers, sync cadence, and staffing allocation. See integration notes at Gleantap Features for implementation help.
Final judgment: prioritize reducing manual workload and hitting a clear revenue or activation gate over building every personalization feature. You can add complexity after the program proves it pays; until then, staff for reliability and measurement, not feature completeness.
Frequently Asked Questions
Straight answer up front: these FAQs are operational fixes, not theoretical answers. Treat each reply as a decision you can implement in the next sprint — which data to wire first, how to validate impact, what to automate, and what not to automate.
What systems should I connect to a fitness member engagement CRM first? Prioritize sources that prove intent and revenue: your scheduling/attendance system, your payment/POS provider, and the membership record that holds status and join dates. Connect one behavioral stream (attendance) and one financial stream (payments) before anything else so segments and offer economics are trustworthy. If you use Mindbody or a similar scheduler, start there and verify that memberid, bookingevent, and attendance map cleanly into the CRM. See Gleantap Features for practical integration notes.
How should I measure ROI for CRM-driven campaigns? Run a randomized holdout or a stepped-wedge rollout and compare cohort outcomes rather than relying on opens or clicks. Your primary outcome should be visits and revenue attributable within a defined window (for example 30–90 days). Compute incremental revenue per treated member = (revenuetreated – revenuecontrol) / n_treated and include offer and staff costs. If your studio is small and underpowered, extend the test period or pool similar cohorts instead of trusting noisy short tests.
How many messages before members call it spam? There is no universal number; tolerance varies by audience and channel. The practical rule is to keep promotional SMS rare, separate transactional sends from marketing, and let members pick frequency in a preference center. Track opt-out, reply rates, and support tickets as your real guardrails. If opt-outs climb after a campaign, throttle frequency and test softer CTAs.
Can a very small studio get value from these tactics? Yes — but scope down. Start with two automations: a time-bound onboarding flow that drives first-repeat visits and a conservative reactivation workflow for members above your economic threshold. Automations pay for themselves by reducing manual follow-ups; the trade-off is an initial monitoring burden that you must staff for (even a few hours per week).
What segmentation mistakes cost studios the most? The usual failures are overlapping audiences that trigger duplicate messages, stale segments based on old data, and segments defined by demographics alone. Implement precedence rules (which segment wins if a member matches two), enforce a freshness SLA for attributes used in filters, and require a minimum population for recurring sends so you do not waste time on micro-segments.
What are the non-negotiable legal points for SMS and email? Record explicit opt-in with timestamp and source, separate transactional messages from promotions, and expose an immediate opt-out. For US rules consult FTC guidance on TCPA considerations. When consent is ambiguous, pause marketing and re-permission the member — losing a contact is better than a carrier complaint or fine.
Concrete example: A two-location studio ran a 60-day stepped rollout for a reactivation offer. They held back 15% of the target cohort as a control, tracked booked-and-attended visits within 30 days, and included the cost of class credits and an estimate of staff follow-up time. The controlled approach let them tighten the offer until incremental revenue exceeded incentive cost — and they avoided incentivizing low-margin churn.
Critical judgment you need now: prioritize measuring visits and net revenue over engagement metrics like opens. Engagement signals are useful for routing, not for proving that a campaign improved retention or LTV. If your reporting can only show opens, fix the booking and visit instrumentation before scaling offers.
Quick operational answers: 1) Wire attendance + payments + membership status first. 2) Validate lift with a randomized holdout or stepped rollout and include incentive and staff cost. 3) Log explicit consent (source + timestamp) and treat ambiguous records as opt-out until re-permissioned.
Next actions you can do this week
- Connect: schedule a nightly sync for attendance and a daily sync for payments; map member_id across both systems.
- Test: pick one reactivation trigger, run a 10–15% holdout, and measure booked+attended visits at 30 days.
- Protect: export consent records, confirm opt-out flows work, and add a preference center link to your next email footer.