
Most B2C teams still stitch booking, POS, payment and analytics data together by hand, which kills velocity and personalization quality. This practical how-to walks you through CDP integration, customer data platform deployment across your existing tech stack, covering source audits, identity resolution, ingestion patterns, activation and privacy-compliant governance. We’ll start with Why a Customer Data Platform Is the Foundation of Omnichannel Engagement and finish with a 60-90 day pilot plan you can run with limited engineering resources.
Why a Customer Data Platform Is the Foundation of Omnichannel Engagement
Key point: CDP integration, customer data platform capabilities create the operational layer you need to treat cross-channel touchpoints as a single customer problem rather than a channel-by-channel problem. When identity, events and segmentation live in one governed store, activation and measurement stop fighting each other over which dataset is correct.
Core capabilities that matter: A practical CDP delivers an identity graph, a unified profile store, a persistent event timeline, a segmentation engine, and activation connectors. Each capability contributes a different kind of leverage: identity enables consistent addressing, the profile store holds state and consent, the timeline supplies temporal logic, the segmentation engine codifies audiences, and connectors operationalize actions.
- Identity graph: resolves identifiers across sources and holds merge rules
- Unified profiles: central traits, consent flags and lifetime revenue
- Event timeline: ordered events for attribution and behavioral logic
- Segmentation engine: reproducible audiences used by all channels
- Activation connectors: reverse ETL and real-time webhooks to push decisions downstream
Practical insight: Teams make two avoidable mistakes. First, they prioritize breadth of connectors over profile quality; dozens of integrations are useless if match rates are low. Second, they treat the CDP as a passive database instead of the orchestration engine that enforces segment definitions, suppression lists and delivery rules across systems.
How this enables true omnichannel workflows
Example flow: A member books a class in Mindbody; payment is recorded by Stripe; GA4 logs a session event. The CDP unifies those inputs into one profile, applies a churn-risk segment, triggers a conditional Twilio SMS, and writes a case to Salesforce for high-touch follow up. That same profile is used to report attribution and frequency capping across email, SMS and in-app channels.
Tradeoffs and limits: Expect tradeoffs between latency and completeness. Real-time activations require streaming or SDK capture and strict schema contracts; historical analysis benefits from batch loads to the warehouse. Also, centralizing customer identity creates operational dependencies: if your CDP ingestion breaks, multiple channels will see stale data. Design monitoring and rollback paths accordingly.
Judgment: If you must choose where to invest first, prioritize identity resolution and consent handling over adding more channel connectors. In practice, a reliable unified profile and clear merge policies deliver measurable gains in personalization and attribution faster than a long list of half-working integrations.
Operational metric to track first: baseline your match rate and data freshness SLA. Use those two metrics to gate activation rollouts and to measure improvements from identity work. See CDP Institute for capability guidance.
Next consideration: map the handful of identity sources that will feed profiles (email, phone, customer_id from your booking system, and payment id), set merge rules, and measure match-rate before you switch on cross-channel campaigns. For integration references, check Gleantap integrations.
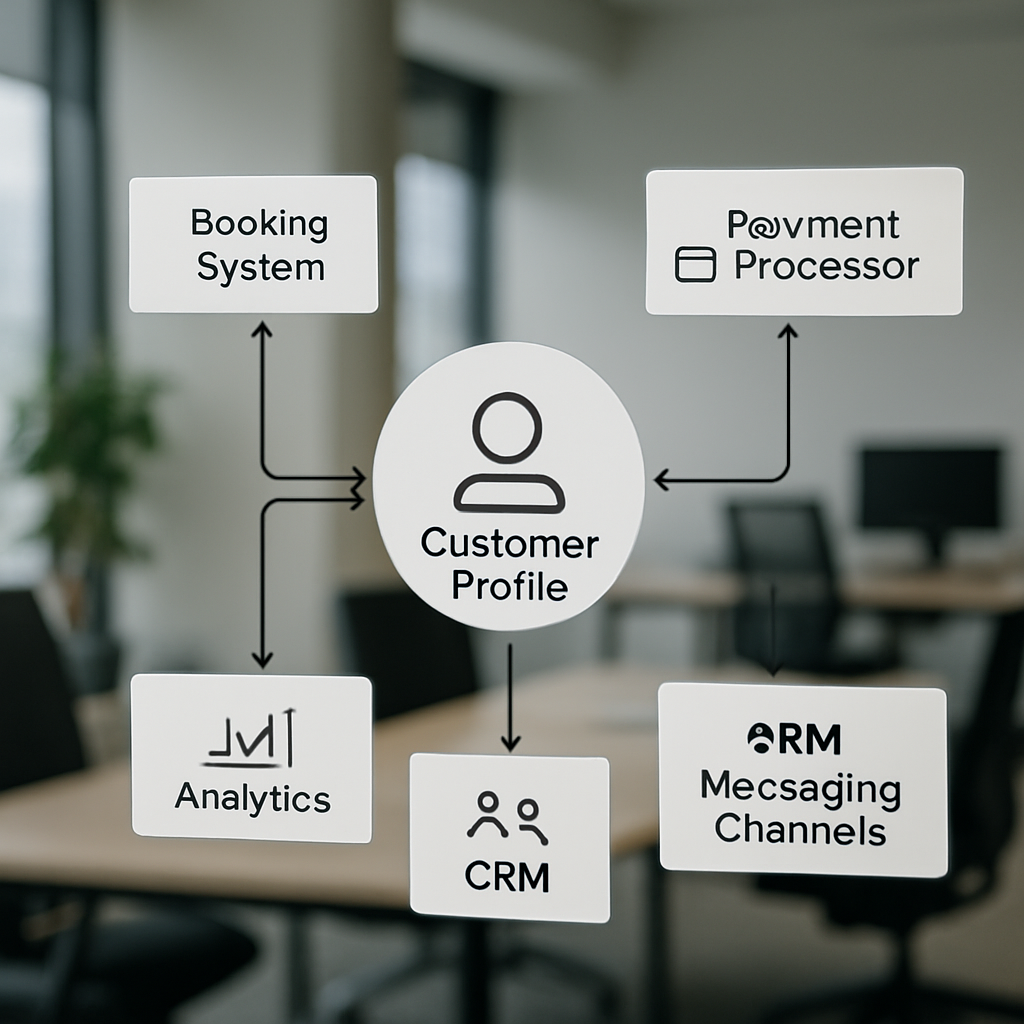
Audit Your Existing Tech Stack and Data Sources
Start with a focused inventory. Build a compact catalog of every system that holds customer signals: booking/attendance, payments, CRM, POS, web/mobile analytics and messaging platforms. For each entry record the owner, primary identifiers, sample event types, and the realistic latency you need for activation — this is the raw material for any successful CDP integration, customer data platform work.
Minimum audit outputs you should produce
| System | Owner | Primary IDs | Key events | Why integrate (value) |
| Mindbody | Ops lead | customer_id, email | booking.created, class.attended | Prevents churn; powers attendance-based offers |
| Stripe | Finance | stripecustomerid, email | payment.succeeded, refund.issued | Revenue attribution and refunds handling |
| GA4 | Growth | clientid, userid | pageview, sessionstart | Behavioral signals for personalization |
Practical prioritization rule: score sources by activation value, data cleanliness, engineering effort, and compliance risk. Then start with the top 3 that unlock revenue or critical workflows rather than trying to onboard every connector at once. That tradeoff — breadth versus depth — is what kills most CDP pilots.
- Scorecard fields: activation impact, matchability (estimated match rate), ingestion complexity, PII/consent exposure
- Quick tests to run: ingest 48 hours of events, compute missing timestamps, and sample identifier overlap between two sources
- Red flags that slow projects: absent user identifiers, timezone-free timestamps, consent flags stored separately or not at all
Concrete example: A mid-size fitness chain pulled 7 days of booking and payment data from Mindbody and Stripe and found email overlap was 68% and timestamp coverage was 95%. They prioritized canonicalizing email formatting, adding server-side booking webhooks for real-time activation, and delaying less critical integrations (loyalty POS) until match rate exceeded 80%.
Limitation to accept early: if your systems lack persistent identifiers you will need either authentication events or a probabilistic stitching layer; both add complexity and lower deterministic match rates. Plan for iterative improvement, not perfect initial joins.
Deliverable you must ship from the audit: a one-page integration plan listing prioritized sources, required identifiers per source, expected latency SLA, data quality gaps, and a compliance map showing where consent flags live and how deletions are executed.
Judgment: invest audit time in identity and consent discovery before building ingestion pipelines. The technical debt of cleaning identifiers later is far higher than delaying lower-value connectors. Remember Why a Customer Data Platform Is the Foundation of Omnichannel Engagement — the CDP can only orchestrate reliably if the inputs are auditable and consistent. Next step: draft merge rules for your prioritized sources and run a match-rate simulation on a sample export.
Integration Patterns and Architecture Choices
Direct statement: Your integration pattern choice – batch, streaming, or API/webhook ingestion – determines whether your CDP is useful for same-day activations or only for reports. This is the single architectural decision that most often defines time-to-value, recurring cost, and operational burden for CDP integration, customer data platform projects.
Core patterns and the tradeoffs
Batch ETL: Nightly or hourly bulk loads into a warehouse (via Fivetran, Airbyte or Stitch) are cheap, simple and reliable for analytics and historical joins, but they are too slow for cart-abandon or live personalization workflows. Use batch when you need completeness and low engineering overhead.
Streaming / SDKs: Event streams captured by tools like Segment or RudderStack, or by using client SDKs, deliver low latency for activation and personalization. The tradeoff is cost per event, stricter schema discipline, and more operational concerns – schema drift and backpressure surface quickly. Use streaming when latency matters.
Server-side webhooks / API ingestion: Transactional systems (payments, bookings) should push authoritative events via webhooks or direct API writes to the CDP. This pattern gives accuracy for financial and lifecycle events but requires secure endpoints, retry/idempotency logic and mature error handling.
- Practical tradeoff: Lower latency costs more operationally and financially; higher completeness requires batch reconciliation jobs and a warehouse.
- Operational constraint: Real-time pipelines need observability, replay windows, and a clear strategy for schema changes; without these you will regress into manual fixes.
- Vendor choice matter: Managed pipelines reduce engineering time but can lock you into pricing models and limit raw data access unless you export to your warehouse.
Recommended hybrid architecture for B2C
Pattern: Capture web and mobile sessions with SDK/streaming for immediate activation, accept server-side transactional events from booking and payments via webhooks, and run scheduled batch ingest for legacy systems and full-history loads into a warehouse (BigQuery, Snowflake or Redshift). Then use reverse ETL (Hightouch, Census) to push audiences back to CRM and ad platforms for operational workflows.
Concrete example: A regional fitness chain uses RudderStack to ingest real-time app events and Stripe webhooks for payments. Daily Fivetran loads feed their BigQuery warehouse for long-term cohort analysis, while Hightouch syncs targeted retention audiences to Salesforce and Facebook Ads. This mix lets staff send immediate appointment reminders while keeping revenue attribution in the warehouse.
Judgment: For most mid-size B2C teams a hybrid approach yields the best return: invest in streaming for high-value, low-latency actions and rely on batch for scale and correctness. Over-investing in universal real-time capture is expensive and often unnecessary.
Design your pipelines so the CDP can produce a single customer view without creating a single point of failure; build fallbacks that serve stale-but-correct profiles when streaming is disrupted.
Operational checklist: enforce schema contracts, add replayable ingestion, implement idempotency for activations, and set cost alerts on per-event pipelines before you enable broad real-time campaigns.
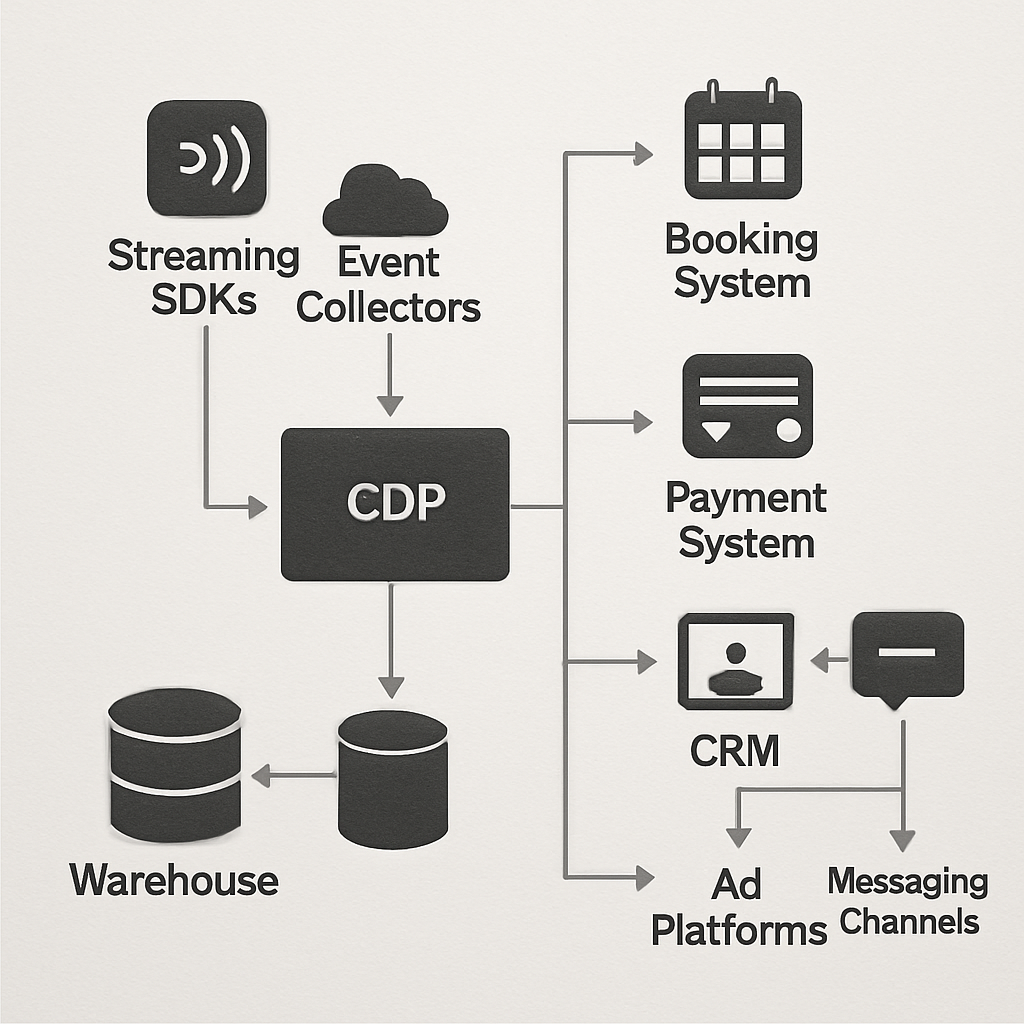
Identity Resolution and Unified Profile Strategy
Identity resolution is the single feature that determines whether your CDP integration, customer data platform yields reliable personalization or just noise. If you fail to define clear matching rules and merge policies up front, downstream segments, activation lists and attribution will be inconsistent and expensive to debug.
Fundamental choices and tradeoffs
Decide early between a conservative, deterministic-first approach and an aggressive probabilistic strategy. Deterministic matching (verified email, authenticated customer_id, phone) gives predictable merges and a low false-positive rate. Probabilistic matching (device fingerprints, IP/time heuristics) increases coverage but raises the chance of incorrect joins and complicates consent handling. The tradeoff is simple: coverage versus trustworthiness.
- Merge policy checklist: prefer verified identifiers, tag source provenance for every trait, never overwrite a verified identifier with an inferred value, keep a timestamped audit trail for merges
- Profile composition rule: store payment processor ids (Stripe/PayPal) as financial handles, not canonical identities; use them for revenue attribution only
- Consent propagation: treat consent flags as first-class profile attributes and propagate them to activation connectors immediately
Concrete example: A family entertainment center used a CDP to stitch online bookings, in-venue POS, and loyalty records. They implemented deterministic joins on email and loyalty_id first, then layered a probabilistic pass to capture kiosks and guest checkout. The result: immediate improvement in campaign precision and a noticeable drop in manual deduplication work for guest services, while the product team tracked a small set of likely false-positives for human review.
You must plan for reversibility. Overmerging is common when teams prioritize match rate over accuracy. Always build an unmerge mechanism and surface a merge_confidence score on profiles so marketing and ops can opt certain customers out of automated workflows until their confidence crosses a threshold.
Practical limitation: probabilistic stitching will never reach deterministic accuracy and can increase privacy risk under GDPR/CCPA if identifiers are inferred without explicit consent.
Operational deliverable: ship a profile contract document that specifies primary identifiers, the merge priority order, conflict resolution rules, retention for PII, and the fields to propagate to activation systems. Make this contract part of your integration acceptance criteria.
Next consideration: run a 7-day match-rate experiment on your prioritized sources, capture merge confidence, and freeze activation on any segment that includes low-confidence profiles until you fix the root joins. For integration references see Gleantap integrations and Segment docs.
Data Modeling, Governance, Privacy and Security
Start with a defensive data model. If profiles contain inconsistent fields or unpredictable event attributes, every activation becomes a risk — wrong offers, suppressed messages, or worse, privacy errors. Design a canonical profile shape and minimal event schema before wiring feeds into your CDP integration, customer data platform.
Schema design and practical modeling choices
Canonical fields over free-form attributes. Define a short list of required profile fields (primary contact handle, verified identifiers, consent state, lifecycle status) and an extensible but governed bag for optional traits. Use snake_case names, a firm timestamp convention (iso8601), and a small vocabulary for event types to avoid downstream mapping work.
Tradeoff to accept: heavy normalization reduces activation errors but makes rapid feature additions slower. If product marketing frequently asks for new traits, expose a controlled feature flag process that lets engineering add attributes after a one-week review rather than allowing ad-hoc fields.
Governance, consent flows and operational controls
Governance is operational work, not paperwork. Implement automated checks: schema-contract testing on ingest, field-level validation (format, length), and a daily profile health job that flags profiles with missing legal-required attributes. Put the results on a small dashboard that ops reviews weekly.
- Consent handling: record consent timestamp, source, and scope as immutable fields; propagate suppression lists immediately to downstream systems.
- Data minimization: prefer tokenization or pseudonymization for activation use; retain raw PII only where required and limit access.
- Retention and purge: automate deletion jobs with verifiable logs and a replay-safe tombstone marker rather than blind deletes.
Practical limitation: aggressive redaction reduces personalization. Tokenization or hashed identifiers let you run lookups and activations without exposing raw PII, but some vendors require cleartext for certain features (for example, carrier-level SMS delivery checks). Expect occasional tradeoffs where you must accept vendor constraints or replace the vendor.
Concrete example: A multi-location fitness brand kept full emails for billing but wrote a service to serve tokenized email hashes for marketing activations. Consent flags in the CDP were the single source of truth and were pushed to Twilio and Salesforce via sync jobs. When a member requested deletion, the system recorded a tombstone, removed raw email from storage, and pushed a deletion event to downstream connectors — that auditable flow avoided a compliance incident during a privacy audit.
Security measures that actually matter: enforce transport and at-rest encryption, implement field-level encryption for high-risk attributes, rotate and scope API credentials, require MFA for console access, and run quarterly access reviews. SOC2 or ISO certification is useful but treat those reports as hygiene — your alerting, key management and data flows are what prevent breaches.
| Control | Where to implement | Why it matters |
| Field-level tokenization | Ingest service / CDP connector | Allows activations without exposing raw PII |
| Consent propagation | CDP mapping + reverse ETL jobs | Prevents sends to suppressed contacts and legal exposure |
| Audit trail & tombstones | Profile store + warehouse | Provides verifiable deletion/compliance evidence |
Key judgment: do not treat privacy as an API toggle. Early investment in tokenization and automatic suppression propagation costs time up front but prevents expensive rewrites and legal risk later.
Operational metric to monitor: track consent propagation latency (time from a consent change to suppression in all activation targets), percentage of profiles with tokenized PII, and the success rate of deletion propagation. Use these to gate activation rollouts.

Activation, Orchestration and Reverse ETL
Direct point: Activation and orchestration are the operational surfaces where a CDP delivers business value — and reverse ETL is the practical plumbing that makes those values visible in CRM, ad platforms, and messaging tools. Treating reverse ETL as an afterthought turns your CDP into a reporting store; treating it as the integration budget item gets you automated outreach, better handoffs to sales, and measurable lifts.
Activation needs are simple in description and fiendish in execution: consistent audience logic, reliable delivery, and traceable outcomes. The engineering problems you will hit first are mapping schema differences, enforcing idempotency for repeated syncs, and ensuring consent/deletion flows travel with the profile to every downstream write target. Practical solution: centralize audience definitions in the CDP, export attribute snapshots rather than raw event streams, and enforce write contracts on each destination.
Design rules that prevent common failures
- Audience-as-code: store segment logic in the CDP and version it; avoid recreating segments in multiple systems.
- Snapshot syncs for enrichment: push an attribute set (customerid, tier, lastactive, churnscore, consentstate) at controlled intervals instead of row-level event writes.
- Destination contracts: require a field-level spec for each target (CRM, ad platform, ESP) including idempotency key and allowed write operations.
- Audit-first pipelines: always emit a reconciliation record to your warehouse so you can compare intended vs applied changes.
Tradeoff to accept: high-frequency reverse ETL (near real-time) reduces latency but multiplies failure modes and cost. For many mid-market B2C teams the sweet spot is sub-hourly enrichment for CRM and minute-level webhooks for critical transactional triggers (bookings, cancellations). Use batch backfills for cohorts and daily revenue syncs.
Concrete example: When a member cancels a class, the CDP marks the profile with churnrisk=true and lastcancellation timestamp. A reverse ETL sync (using Hightouch or Census) writes a field snapshot to Salesforce within 5 minutes so the membership team sees the change in the contact record, while a webhook fires a conditional Twilio SMS for immediate retention outreach. The two paths — CRM enrichment and real-time messaging — are treated separately but driven from the same authoritative profile.
Important: reverse ETL is state synchronization, not an event bus. Design it to correct state in destination systems rather than replay every event.
A frequent misunderstanding is that more destinations equals more value. In practice, more destinations without clear field contracts create data drift and compliance risk. Limit initial write targets, prove the closed-loop measurement (send → engagement → CRM update → pipeline movement), then scale. Use Gleantap integrations as a reference for connector capabilities and consent propagation behavior.
Operational deliverable: a reverse ETL runbook that lists each destination, the exact fields to write, sync frequency, idempotency key, retry policy, and GDPR/CCPA handling steps. Ship this before you enable any automated writeback.
Implementation Roadmap, Testing and Measurement
Start with a gated pilot, not a big-bang rollout. Build a short, measurable sequence of work that proves ingestion, identity stitching, and one activation path before scaling to every source and channel.
60–90 day phased roadmap (practical cadence)
- Phase 0 — Prep (days 1–7): finalize owners, freeze the canonical profile schema, and produce a minimal event catalog that lists the one-time fields required for target activations. Assign a single data owner and an integration engineer.
- Phase 1 — Core ingestion (weeks 2–4): wire authoritative sources via webhooks or API (booking, payments, analytics), implement basic transformation and tokenization, and run a 7-day ingest sanity check to validate timestamps, IDs and duplicate rates.
- Phase 2 — Identity and shallow activation (weeks 5–8): enable deterministic joins, tag merge confidence, and switch on one low-risk activation (for example, appointment reminders via Twilio or a CRM enrichment sync). Keep a canary cohort under manual review.
- Phase 3 — Pilot measurement and hardening (weeks 9–12): run lift tests using holdouts, reconcile activation logs with warehouse records, formalize retention/cleanup jobs, and document runbooks for downstream owners before wider rollout.
Roles that make this work: dedicate a data owner (business lead), an integration engineer, a privacy officer, and a measurement analyst. Decision bottlenecks occur when ownership is split; designate who can green-light go/no-go gates for each phase.
Testing and validation strategy
Tests to run (practical list): contract validation for all incoming payloads, identity merge simulations with synthetic edge-cases, high-volume ingestion stress runs, end-to-end activation dry-runs (messages written to a sandbox), and reconciliation jobs that compare intended writes to applied changes in destinations.
Important tradeoff: extensive test coverage reduces risk but slows time-to-value. Use progressive exposure: run exhaustive tests in staging, a short canary on real traffic, then expand only after acceptance criteria are met. Production-only testing is risky; over-testing in staging can obscure environment differences — include a brief real traffic canary step.
Measurement approach: treat campaigns as experiments. Use randomized holdouts or geo-based controls, instrument a small set of primary KPIs (identity coverage, ingestion latency percentiles, profile completeness, and activation delivery reliability), and capture secondary business outcomes (engagement, conversion, retention) with attribution windows tied to the activation timeline.
Concrete example: A regional wellness studio implemented the pilot above: they ingested booking webhooks and Stripe events, enabled deterministic joins on verified email, and ran a two-week holdout where the CDP-driven SMS workflow was only applied to half of overdue-booking customers. The team used reconciliation logs to find mapping errors, corrected merge rules, and then expanded the workflow after the canary showed improved follow-up speed and clearer CRM handoffs.
Common mistake: equating a high raw event volume with readiness. The right signal is consistent, attributable profiles and reliable delivery to one channel — not raw throughput.
Pilot acceptance checklist: owners assigned; canonical schema validated; identity match coverage agreed with stakeholders; successful canary activations in sandbox and production; reconciliation checks passing for 48 hours; documented rollback and suppression procedures.

Next consideration: pick the single activation and the single attribution method you will use to declare pilot success, then lock both before you write more connectors.
Real World Integration Examples, Partner Matrix and Appendix Guidance
Direct point: Integration choices define how quickly your teams can act on signals. Pick patterns and partners that reduce friction for identity resolution, consent propagation and downstream writes — not the ones with the longest connector list.
A few realistic mappings you should have sketched before any engineering work: link e commerce systems to analytics and personalization (Shopify → GA4 + CDP for product affinity), funnel payment events into revenue attribution and billing reconciliation (Stripe → CDP → warehouse), and make booking/attendance the source of truth for lifecycle state (Mindbody/Zen Planner → CDP → CRM + messaging). These are the practical paths that make CDP integration, customer data platform projects operational rather than theoretical.
Concrete use case
Concrete example: A regional retail chain used Fivetran to backfill two years of Shopify orders into BigQuery, captured storefront events with Segment for session-level personalization, and set up Hightouch to sync a churn-risk trait into Salesforce hourly. The CDP served as the authoritative profile; marketing used the same segment logic to run personalized email in Braze and targeted ads through Facebook. The team limited writebacks to two systems for the first 60 days to keep reconciliation manageable.
Key tradeoff to plan for: Real-time activations cost more and require strict schema discipline and monitoring. If your objective is predictable, auditable campaigns, start with snapshot-based reverse ETL and one real-time webhook flow for critical actions (cancellations, refunds). Scale low-latency pathways only after match-rate and consent propagation are stable.
| Vendor | Typical role in a CDP stack | Practical tradeoff / tip |
| Fivetran | Managed batch ingestion to warehouse | Reliable for historical loads; limited control over transform timing |
| Segment | Streaming and client SDK capture | Low latency for personalization; higher cost per event and schema discipline required |
| RudderStack | Open-source friendly streaming alternative | Good for self-hosting teams; more ops overhead |
| Hightouch / Census | Reverse ETL / audience sync | Makes CRM and ad syncs simple; treat them as state syncs, not event buses |
| Braze | Email / in-app orchestration | Feature-rich messaging; ensure consent flags reach Braze before sends |
| Twilio | SMS / Voice delivery | Fast and reliable; carrier-level constraints may require cleartext phone numbers |
| Snowflake / BigQuery / Redshift | Long-term analytics and reconciliation | Essential for attribution; expect storage and compute tradeoffs |
| Shopify / Stripe / Mindbody | Authoritative sources (orders, payments, bookings) | Treat as primary identifiers — map their IDs carefully and avoid overwriting verified fields |
Judgment: Avoid the temptation to connect every downstream tool at once. A tightly scoped matrix of source → CDP → one analytics sink → one activation sink reduces debugging time and forces you to solidify identity, consent and reconciliation practices before scale.
Appendix guidance you should include with any integration handoff
- Event mapping CSV: columns for sourceevent, canonicalevent, requiredattributes, samplepayload, latencyrequirement, and consumernotes.
- API readiness checklist: authentication method, scopes, rate limits, retry behavior, expected error codes, idempotency key use, and backfill endpoints.
- Monitoring checklist: ingestion error rate, schema drift alerts, profile match-rate trend, consent propagation latency, and reconciliation delta between intended vs applied writes.
Operational limitation to accept: Many vendors promise universal reconciliation; in practice, reverse ETL will be eventually consistent. Design business processes that tolerate short windows of inconsistency and build reconciliations to correct destination state.
Appendix deliverable: ship a single ZIP containing the event mapping CSV, API checklist, a short partner matrix (this table), and a runbook that lists rollback steps and contact owners. Make that ZIP the handoff to operations.
Frequently Asked Questions
Straight answer up front: these are the operational questions that stall most CDP integration, customer data platform projects — not the marketing pitch. The answers below focus on tradeoffs, failure modes, and what to lock down before you flip switches in production.
How long will a realistic pilot take? Expect a focused pilot that proves ingestion, identity stitching and one activation channel to take somewhere between six and twelve weeks depending on engineering bandwidth and data cleanliness. The variable that stretches timelines fastest is messy identifiers and missing consent metadata; clean those first or budget extra time.
Which sources cause the most headaches? Legacy booking and point-of-sale systems, custom databases without stable APIs, and vendor exports that strip timestamps or identifiers create the most friction. When a source is hard, plan for a small middleware service that normalizes payloads, enforces timestamps, and issues retries rather than trying to bolt the raw export straight into the CDP.
Batch versus streaming — how to decide? Use streaming for actions that require sub-minute response (cart abandonment, urgent retention nudges). Use batch for historical joins, large backfills and low-value syncs. Most teams benefit from a hybrid approach where streaming covers high-value real-time paths and batch handles scale and reconciliation.
Can a CDP replace our data warehouse? No. Treat the CDP as the operational profile and activation engine; treat the warehouse as the long-term analytic store and reconciliation source. You will need both and should design reverse ETL and export jobs that keep them consistent.
How do we correctly handle consent and deletion requests? Record consent scope, source and timestamp on the profile. Automate suppression propagation to every activation target and create auditable tombstone records in your warehouse. Manual propagation or one-off scripts are the usual cause of compliance incidents.
What metrics prove the integration is working? Track identity coverage (percentage of profiles with at least one verified identifier), ingestion latency percentiles, reconciliation deltas between intended and applied writes, and early business signals tied to the pilot activation (open rate lift, conversion or booking recovery). Avoid judging readiness on raw event volume alone.
Vendor lock-in and data access — what should we watch for? Prioritize vendors that let you export raw event streams and profile snapshots to a warehouse (for audit and long-term analysis). If a connector is proprietary or limits exports, treat it as a tactical integration and avoid embedding critical business logic inside that vendor.
Concrete example: A mid-size wellness operator ran a pilot that captured bookings via server webhooks, payments via Stripe events, and session data via a streaming SDK. They prioritized deterministic joins on verified email and performed two canary runs: first with CRM enrichment only, then with real-time SMS for cancellations. The staged approach exposed mapping errors early and kept the membership team from sending incorrect messages during the early weeks.
Quick rule of thumb: freeze your merge rules and consent handling before you enable any automated writebacks. Small identity fixes later are costly — larger, controlled fixes are cheaper and safer.
Common misunderstanding: teams assume higher match rates automatically mean better personalization. In practice, aggressively increasing coverage with probabilistic joins often introduces false positives that reduce campaign performance and increase support work. Favor deterministic joins for revenue-driving segments and gate lower-confidence profiles out of automated flows.
Next actions you can implement this week: 1) run a 7-day export of your top three sources and compute overlap on verified identifiers; 2) draft merge-priority rules and a simple unmerge process; 3) configure one snapshot reverse ETL to a CRM and a single real-time webhook for an urgent trigger (cancellations or refunds). These three steps get you from exploration to a safe, measurable pilot fast.

Written by
Sarah Kim
Sarah is a CRM and customer data specialist who helps B2C brands turn raw data into personalised experiences. With a background in customer success, she writes about segmentation, customer journey mapping, and making the most of your CRM platform.
Recent blog posts
Back to blog

Ready to Run Successful Marketing Campaigns and Grow Your Business?
Gleantap helps you unify customer data, track behavior patterns, and automate personalized campaigns, so you can increase repeat purchases and grow your business.
Ready to Run Successful Marketing Campaigns and Grow Your Business?
Gleantap helps you unify customer data, track behavior patterns, and automate personalized campaigns, so you can increase repeat purchases and grow your business.